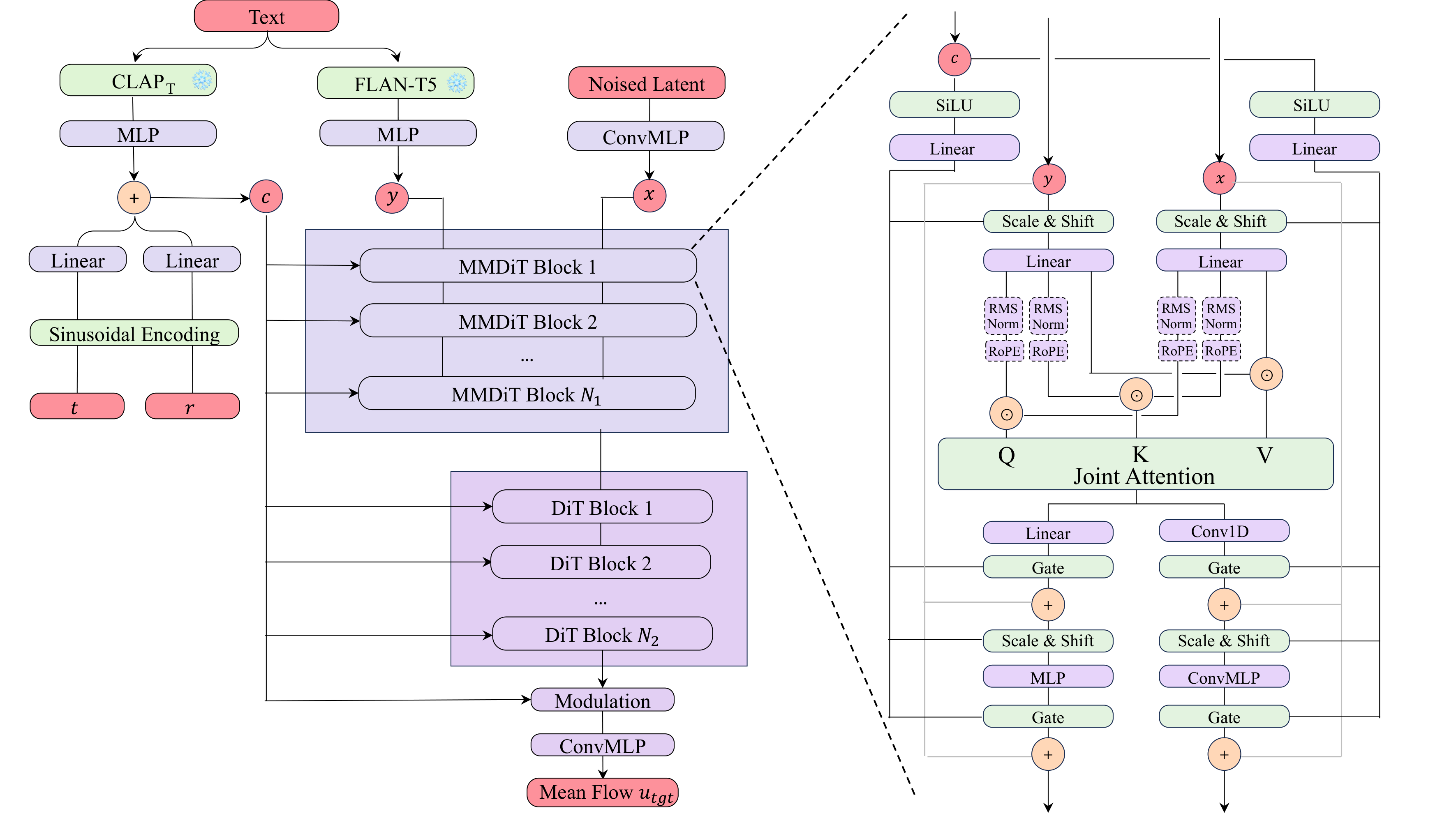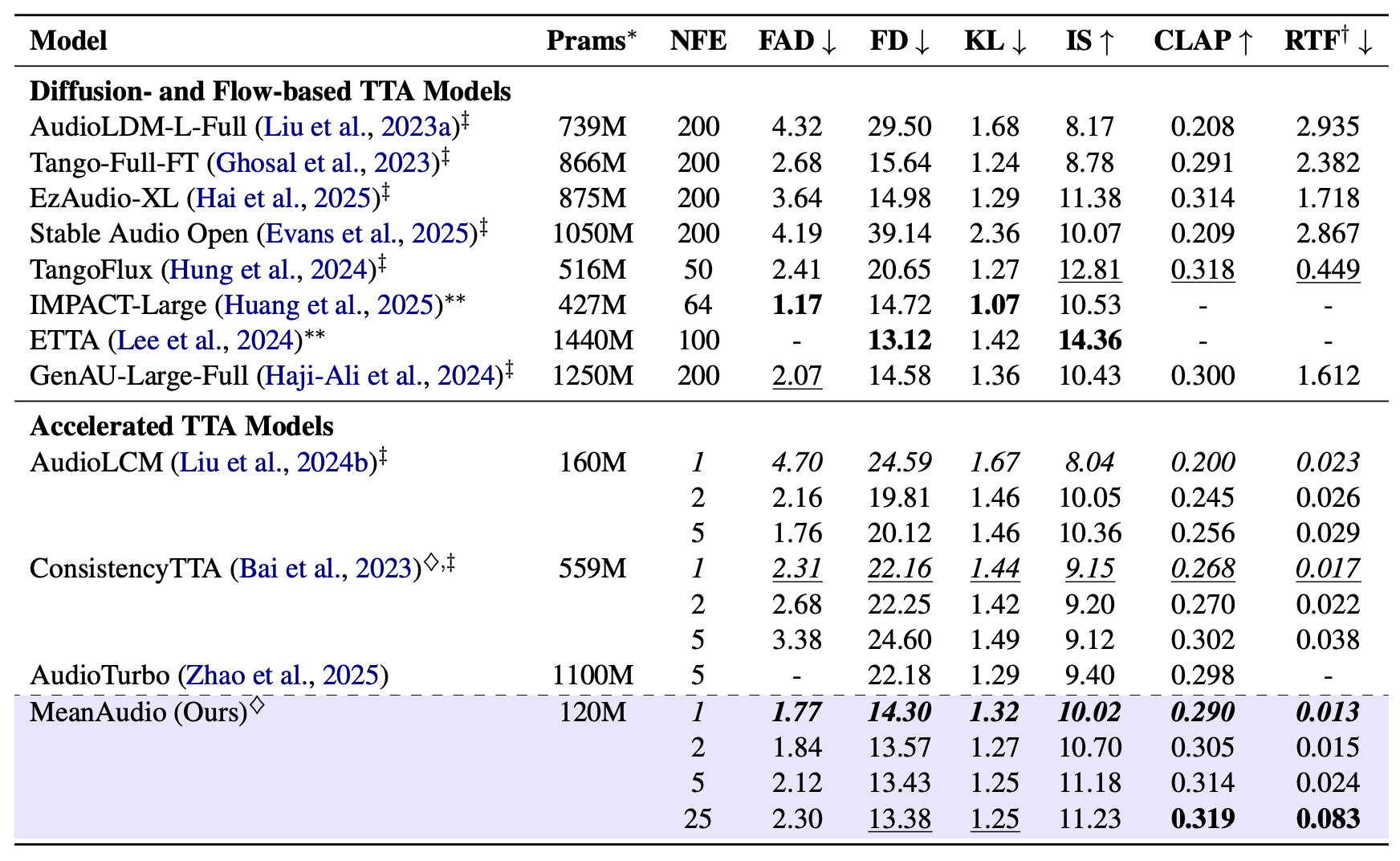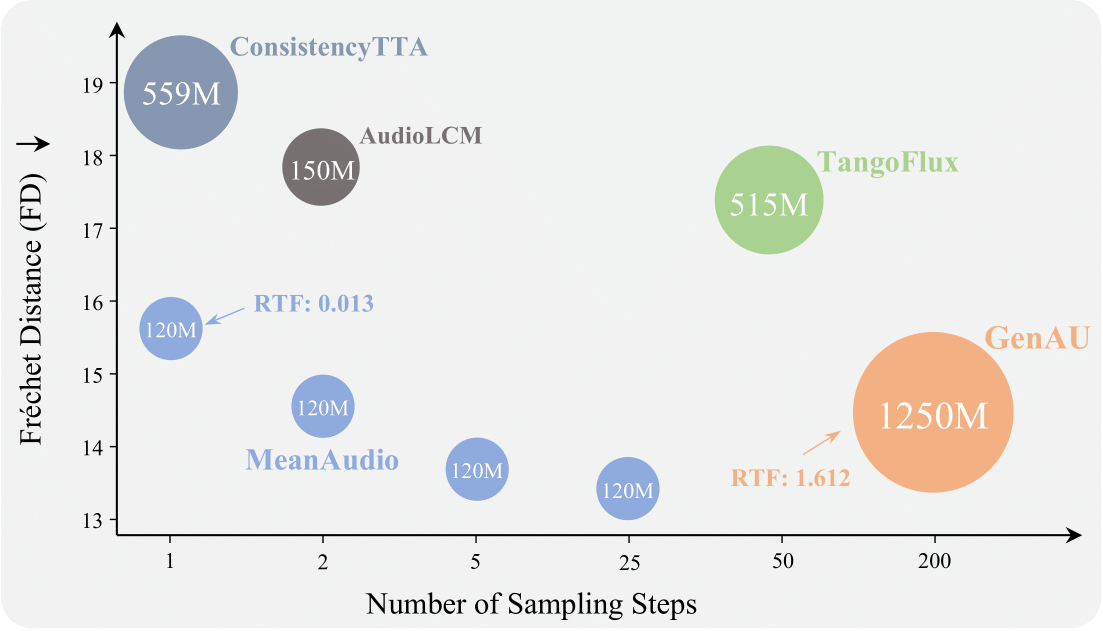
MeanAudio is a novel MeanFlow-based model tailored for fast and faithful text-to-audio generation. It can synthesize realistic audio in a single step, achieving a real-time factor (RTF) of 0.013 on a single NVIDIA 3090 GPU. Moreover, it also demonstrates strong performance in multi-step generation.